- About Us
-
Space delivers data-driven insights, streamlined processes, and exceptional user experiences that drive success through services like data analytics, Generative AI, Generative AI, process automation, and UX/UI design.
Empower your teams to make smarter decisions.
Gain a competitive edge and optimize your business.

Witness the impact of our AI service on a business's success.


Streamline your data processes for maximum efficiency.

Elevate your brand with our innovative designs.

Witness the impact of our AI service on a business's success.

Maximize product impact with our dedicated management services.

Achieve your project goals with our expert support Team.
-
Space Products leverage cutting-edge technologies to streamline workflows, reduce errors, and empower data-driven decision-making. Experience the future of business automation.
Transform your business operations with Space Products.

Witness the impact of our AI service on a business's success.

Streamline your data processes for maximum efficiency.
-
Space partners with businesses across a wide range of industries to optimize operations and drive success through data-driven insights and streamlined processes.
Explore our industry solutions and discover how we can help your business thrive.









Table of Contents
Building Scalable Data Pipelines for Life Sciences
- Introduction
- Challenges in Life Sciences Data
- Key Components of a Scalable Data Pipeline
- Data Engineering Services in Life Sciences
- Cloud Data Pipeline Architecture
- Architecture Diagram
- Cloud Benefits
- Best Practices
- Conclusion



Introduction
In the life sciences, the explosion of data from genomics, clinical trials, imaging and IoT devices necessitates robust data engineering services to build cloud data pipelines that are scalable, reliable, and compliant with regulations like HIPAA and GDPR. These pipelines process massive datasets, integrate heterogeneous sources, and enable advanced analytics for precision medicine and research. This blog explores the technical architecture, data engineering services, and cloud data pipeline strategies tailored for life sciences.

Challenges in Life Sciences Data
Life sciences data is defined by:
- Volume: Whole-genome sequencing generates terabytes per sample.
- Variety: Structured clinical data, unstructured notes, and imaging (e.g., DICOM).
- Velocity: Real-time streams from high-throughput sequencers or biosensors
- Veracity: Data quality and compliance with regulatory standards are critical.
- Value: Insights from integrated datasets drive research and clinical outcomes.
Data engineering services and cloud data pipelines must address these challenges to ensure scalability and performance.

Key Components of a Scalable Data Pipeline
1. Data Ingestion
Ingestion involves collecting raw data from diverse life sciences sources:
- Genomic Data: FASTQ, BAM, or VCF files from sequencing platforms.
- Clinical Data: EHRs in FHIR or CSV formats.
- Imaging Data: DICOM files from MRI or CT scans.
- IoT Data: Real-time biosensor streams capturing physiological metrics.
Technologies:
- Azure Event Hubs: Provides high-throughput, partitioned streaming for genomic or sensor data ingestion at scale.
- Azure IoT Hub: Serverless, scalable ingestion platform optimized for real-time IoT device telemetry.
- REST APIs: Used for structured clinical data ingestion, often via Azure API for FHIR for interoperability.
Example: A cloud data pipeline using Azure Event Hubs streams FASTQ files into Azure Data Lake Storage Gen2, partitioned by sample ID for efficient downstream processing.
2. Data Storage
Scalable storage supports diverse formats and compliance needs.
Options:
- Distributed File Systems: Azure Blob Storage or Hadoop HDFS for genomic and imaging data storage.
- Data Lakes: Azure Data Lake Storage Gen2 or Databricks Delta Lake for centralized storage with ACID transactions.
- Databases:
1. SQL: PostgreSQL for structured clinical data, using extensions like pg_trgm for fuzzy matching.
2. NoSQL: MongoDB for unstructured clinical notes or FHIR JSON.
3. Data Processing
Processing transforms raw data for analysis, a core function of data engineering services.
Frameworks:
- Apache Spark: Azure Databricks handles distributed processing of genomic datasets for tasks like variant calling.
- Apache Beam: Supports unified batch and stream processing, integrating with bioinformatics libraries.
- Azure Data Factory: Orchestrates workflows in cloud data pipelines.
Example Pipeline: A genomics pipeline on Azure Databricks aligns FASTQ reads using BWA-MEM and calls variants with GATK, orchestrated via Azure Data Factory and stored in Azure Data Lake Storage Gen2
4. Data Integration and Transformation
Integration combines genomic, clinical, and imaging data, a key offering of data engineering services.
Tools::
- Azure Synapse Analytics: Performs scalable data transformations within data warehouses to create integrated, analytics-ready datasets.
- Azure Data Factory: Orchestrates and automates ETL workflows across cloud data pipelines with built-in scheduling and monitoring.
- Azure API for FHIR: Offers a fully managed, standards-compliant HL7 FHIR interface that enables secure, scalable interoperability and exchange of clinical healthcare data.
Example: An Azure Data Factory (ADF) workflow orchestrates a cloud data pipeline that extracts EHR data, transforms VCF files, and loads the integrated data into Azure SQL Database for downstream analytics.
5. Data Analysis and Machine Learning
Analytics extract insights from processed data.
Technologies::
- Azure Machine Learning with TensorFlow/PyTorch: Enables scalable training and deployment of deep learning models (e.g., for image segmentation) using built-in support for TensorFlow and PyTorch on Azure ML compute clusters or GPU-enabled VMs.
- Azure Machine Learning with scikit-learn: Supports classical ML tasks such as clustering patient cohorts using scikit-learn, with integrated tracking, reproducibility, and automated ML features.
- Azure Machine Learning + MLflow Integration: Tracks experiments, manages model versions, and deploys trained models as REST endpoints using Azure ML’s native support for MLflow tracking and model registry.
Example: A PyTorch-based Convolutional Neural Network (CNN) deployed on Azure Kubernetes Service (AKS) performs real-time inference on DICOM images as part of an Azure cloud data pipeline.
6. Monitoring and Governance
Ensuring reliability and compliance is a critical data engineering service.
Tools:
- Azure Monitor + Azure Metrics + Azure Dashboards: Provides comprehensive monitoring and visualization of pipeline performance in Azure cloud data workflows.
- Azure Data Factory Data Flow & Azure Purview Data Quality: Ensures data validation and quality checks to maintain compliance across data pipelines.
- Azure Purview Data Catalog: Manages metadata and tracks data lineage to provide governance and discoverability within the Azure ecosystem.
Best Practice: Use Azure Role-Based Access Control (RBAC) to enforce fine-grained permissions and secure access management, combined with strong encryption standards like AES-256 for data at rest and TLS for data in transit to meet HIPAA and GDPR compliance requirements.

Data Engineering Services in Life Sciences
Data engineering services are essential for designing and maintaining cloud data pipelines. Key services include:
Pipeline Design:
- Collaborate with bioinformaticians to define requirements for genomic and clinical data integration.
- Design schemas supporting FHIR-compliant clinical data and VCF files for genomic variants.
- Architect for scalability to handle petabyte-scale datasets leveraging distributed systems like Azure Data Lake Storage Gen2 and Spark.
ETL and Integration:
- Connect to sequencing platforms, EHRs, and imaging systems through REST APIs, Azure API for FHIR, or secure file transfers.
- Normalize data by mapping clinical codes to standards like SNOMED CT using Azure Data Factory or Databricks transformations.
- Orchestrate workflows with Azure Data Factory, Azure Synapse Pipelines, or Apache Airflow running on Azure Kubernetes Service (AKS).
Optimization
- Parallelize compute-intensive tasks using Azure Databricks (Spark) or Azure Batch for HPC workloads.
- Cache frequently accessed metadata using Azure Cache for Redis.
- Optimize costs with serverless compute options like Azure Functions or Synapse serverless SQL pools.
Compliance and Security:
- Collaborate with bioinformaticians to define requirements for genomic and clinical data integration.
- Design schemas supporting FHIR-compliant clinical data and VCF files for genomic variants.
- Architect for scalability to handle petabyte-scale datasets leveraging distributed systems like Azure Data Lake Storage Gen2 and Spark.
Maintenance
- Monitor pipeline health and performance with Azure Monitor and Azure Dashboards.
- Track errors and exceptions using Azure Application Insights or Sentry (self-hosted or SaaS).
- Version data and code using Azure DevOps, Git, and Delta Lake versioning on Azure Databricks.
Example
A data engineering team uses Azure Data Factory to orchestrate a cloud data pipeline that processes FASTQ files with GATK on Azure Databricks, storing results securely in Azure Synapse Analytics, with data protected by Azure Key Vault encryption and strict RBAC policies.

Cloud Data Pipeline Architecture
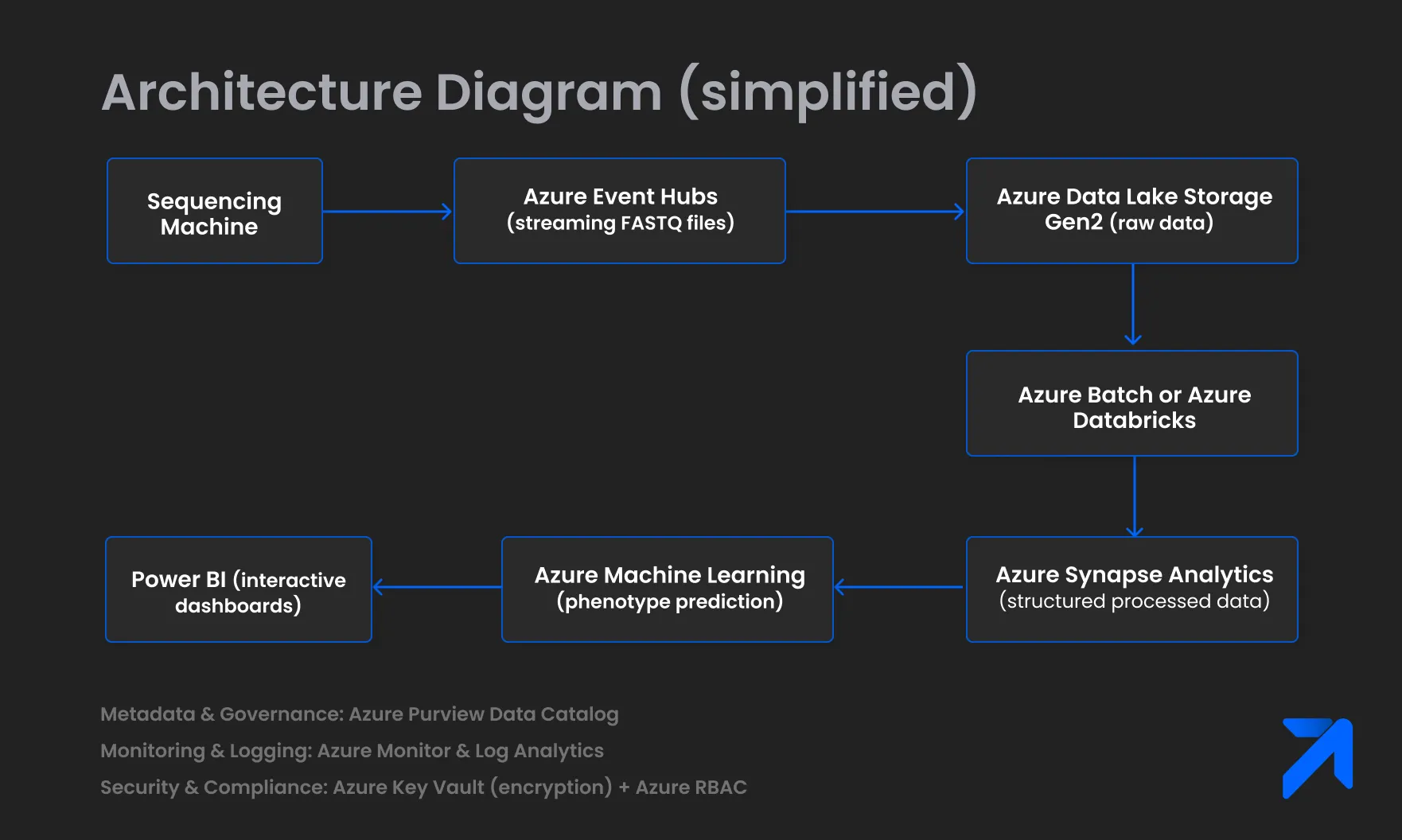
Cloud data pipelines leverage managed services for scalability. Below is an Azure-based architecture:
Ingestion
- Source: Azure Event Hubs streams FASTQ files; Azure IoT Hub handles biosensor data ingestion.
Storage:
- Raw Data: Azure Data Lake Storage Gen2 with Cool and Archive tiers for long-term archival.
- Metadata: Azure Purview Data Catalog for metadata management and data lineage.
- Processed Data: Azure Synapse Analytics dedicated SQL pools or serverless SQL pools for structured data storage.
Processing
- Compute: Azure Batch or Azure Databricks runs Nextflow workflows for sequence alignment and variant calling.
- Orchestration: Azure Data Factory or Azure Logic Apps manage workflow orchestration.
Transformation
- Tool: dbt running on Azure Databricks or Synapse SQL transforms data within the warehouse.
- Interoperability: Azure API for FHIR exposes clinical data APIs compliant with HL7 FHIR standards.
Analysis
- ML: Azure Machine Learning service for phenotype prediction and model training/deployment.
- Visualization: Power BI provides interactive dashboards and reports.
Monitoring and Governance:
- Monitoring: Azure Monitor and Azure Log Analytics capture metrics and logs.
- Governance: Azure Purview enforces data access policies and governance.
- Compliance: Azure Key Vault manages encryption keys (AES-256), and Azure RBAC enforces role-based access control.

Architecture Diagram
Cloud Benefits
- Scalability: Auto-scale compute resources dynamically with Azure Kubernetes Service (AKS), Azure Functions, and Databricks.
- Cost Efficiency: Serverless compute options like Azure Functions and Synapse serverless SQL pools help reduce costs by charging only for usage.
- Managed Services: Azure Data Factory and Azure Purview simplify ETL orchestration and data governance.
- Compliance: Azure regions provide robust data residency, privacy, and compliance certifications (HIPAA, GDPR, etc.).
Best Practices
- Modularity: Use containerized tools and microservices deployed via Azure Kubernetes Service for flexible, maintainable pipelines.
- Scalability: Leverage Azure auto-scaling features and serverless offerings to handle workload fluctuations efficiently.
- Versioning: Implement data and code versioning with Delta Lake on Azure Databricks and source control via Azure DevOps Git repositories.
- Compliance: Encrypt data at rest with Azure Storage encryption and in transit with TLS; enable comprehensive audit logging with Azure Monitor.
- Testing: Validate data quality and integrity using Azure Data Factory Data Flows or integrate Great Expectations within Databricks.
- Cost Management: Monitor and optimize cloud spending using Azure Cost Management + Billing dashboards and alerts.

Conclusion
Data engineering services and cloud data pipelines are essential for processing life sciences data at scale. By leveraging technologies such as Azure Event Hubs, Azure Databricks (Spark), Nextflow workflows on Azure Batch or AKS, and managed platforms like Azure Synapse Analytics and Azure Machine Learning, organizations can build scalable pipelines capable of handling petabyte-scale datasets while maintaining strict compliance. These solutions empower breakthroughs in genomics, clinical research, and precision medicine by enabling faster, more reliable, and secure data-driven insights.
Read Less

By Shreeman Sahu
Senior IT Specialist
Read other blogs
Your go-to resource for IT knowledge. Explore our blog for practical advice and industry updates.




Discover valuable insights and expert advice.
Uncover valuable insights and stay ahead of the curve by subscribing to our newsletter.
Download Our Latest Industry Report
To know more insights!
PRODUCTS






